Everybody lives their own version of “Off Avignon”, France’s gigantic summer festival of performing arts.
This may be true for any experience, but what makes “Off Avignon” different from, say, music festivals, is that there are no “headliner” shows that everyone will see. The program features 1700 different plays, even the ones that play in “big” theaters will only be seen by a fraction of the 300,000 festival-goers.

Choose wisely! Pick the right shows and you will experience the full spectrum of beautiful and difficult emotions, laugh to tears, find inspiration and come back renewed.
Pick the wrong shows and you’ll only get the “difficult emotions” part; prominently featuring the frustrated wait for the play to end.
But then again, there are 1700 shows in the program! Where do we even begin? The importance of choosing well, coupled with the impossibility of actually reading the program, makes Off Avignon a fun use-case for AI-assisted research.
Requirements
The exercise begins with writing down what we want.
Research shows playing at Off Avignon 2025 and pick 20 recommendations for plays that I may like, based on the requirements below.
Add some notes on what you like:
I like shows that are moving, profound, inspiring, touching on the essence of the human condition, inventive (experimenting with the boundaries of their format), etc. One-person shows are fine, but I need them to be GOOD.
Make sure to mention what you don’t want:
NO popular-appeal comedy please. NO shows for kids.
And since we’re social creatures, let’s take into account what others are saying:
Pay special attention to shows that received favorable coverage, especially as personal coup-de-coeurs and highlights from small independent publications. Also flag for me any shows that are widely discussed, controversial or otherwise prominent in the media coverage.
Now that we have written down the prompt, what do we actually do with it?
Agentic search
Modern chat assistants such as OpenAI’s o3 and Google’s Gemini 2.5 Pro are agents, not LLMs. When we send them a text query, they don’t just run the LLM once to generate the response based on whatever knowledge is baked into the model. Instead, they run the LLM in a loop, letting it plan its work, decide on how to source additional information, run multiple rounds of web search queries, etc.
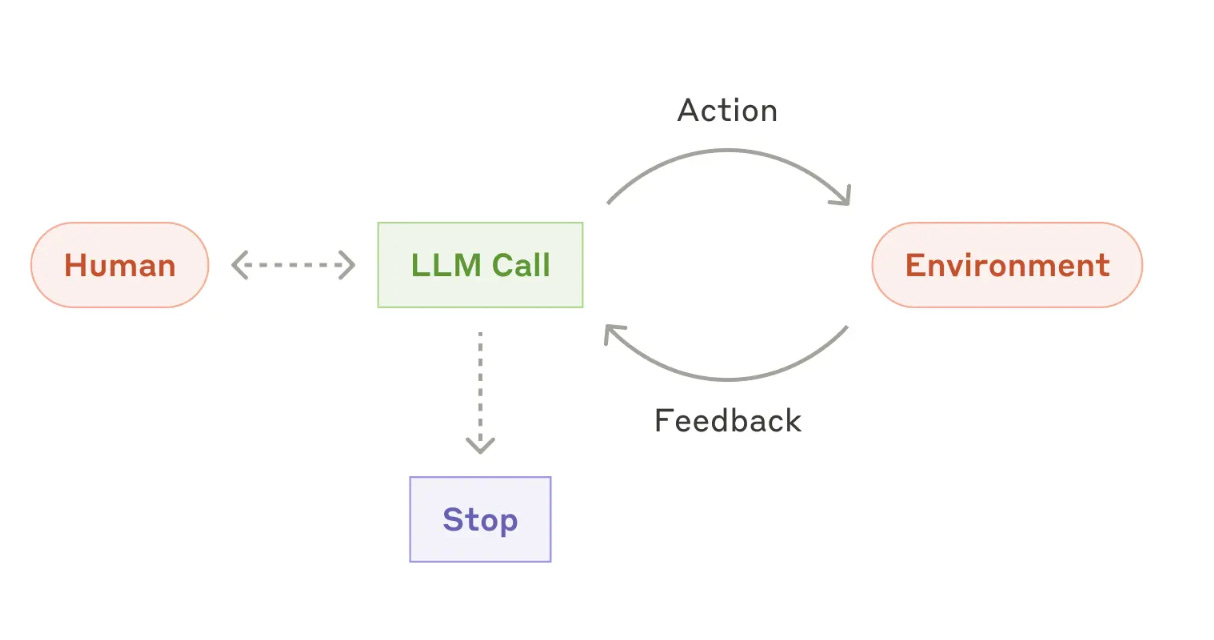
Let’s try OpenAI’s o3:
This “agentic loop” is run server-side, but the agents display hints on the intermediate steps while the loop is running:
After two minutes, the assistant decides it has enough material to compile the final report, neatly organized into topical sections:

Cool! But I’m a bit skeptical about the resulting list. In the 2 minutes it took to handle the request it only browsed a dozen or so websites, and overall seemed a bit too eager to wrap up the search:

I want the agent to source significantly more show ideas, and then do the difficult work of picking out those that stand out the most. I want it to work harder.
Deep research
Selecting “Deep research” in ChatGPT or Gemini keeps the agent running for longer and browse more websites needed to answer our request. Let’s try it in Gemini, which first introduced deep research back in December 2024.

This time the agent is more eager to search, retrieving ~20 websites in a single go, over multiple rounds:
It also aims to source a longer preliminary list first, before trimming it down with further research:

Results
20 minutes later, we get the resulting report, organized in a neat table:

All this agentic magic is making my annual festival research exercise much easier.
When I tried it for the first time in 2023, I needed to take care of the data sourcing and the not-really-agentic loop myself: this meant writing programs to scrape the festival program, and then to feed each show description to an LLM via a separate API call.
I feel ambivalent about all this progress: it’s liberating (in terms of freeing up time) and it’s effective, but the unused muscles atrophy.
As the AI does more hard things for us, we better keep finding new hard things to do ourselves.