I was part of the team that developed Ledger, an experimental, distributed, local-first data store. It was in development between 2016 and 2019. While the project was developed in the open, we never published any engineering commentary on how it went and what we learned from it. Here’s my attempt to fill in that gap.
(These are my personal notes and not an official communication from Google.)
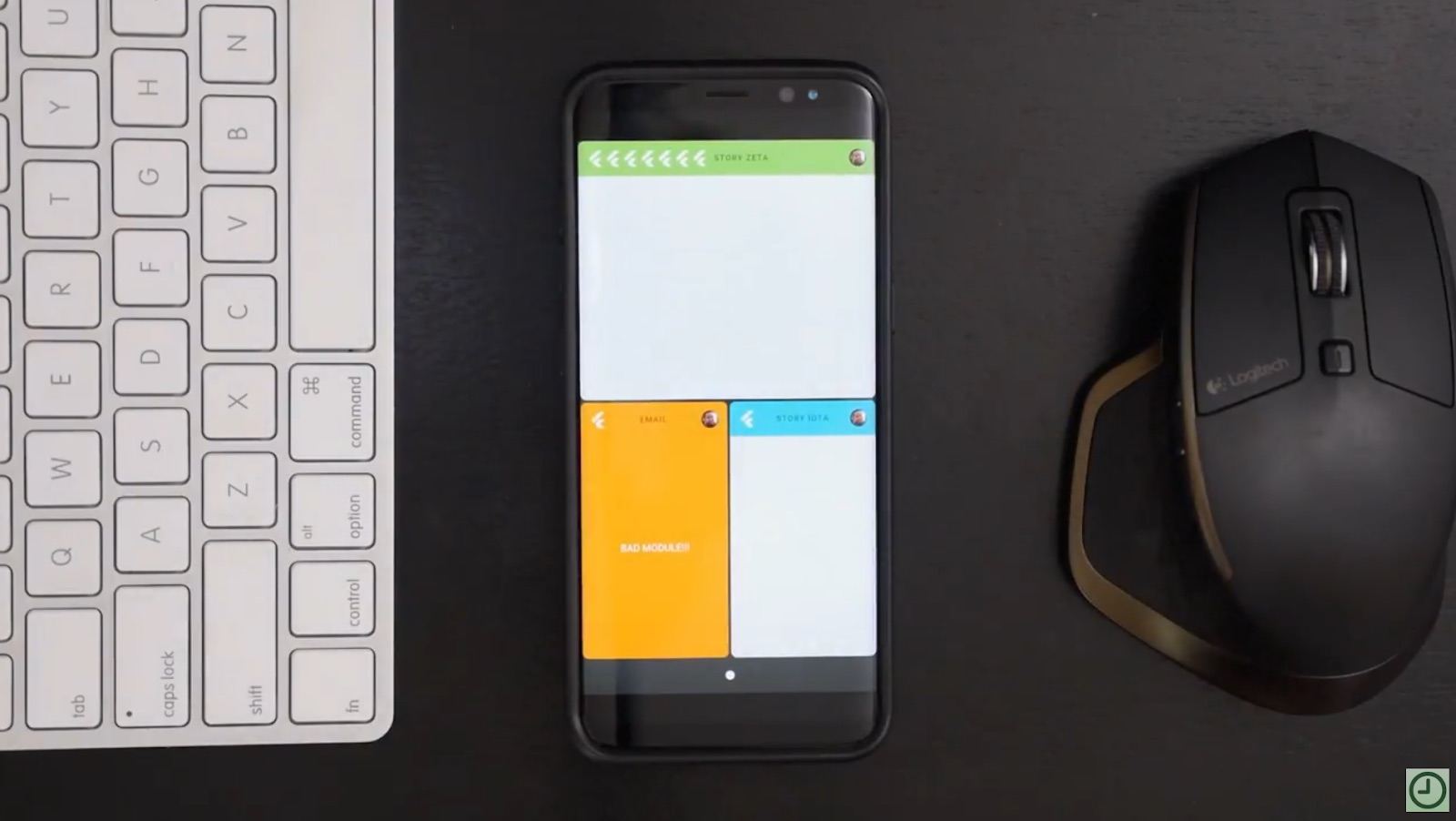
Ledger was the data store underlying story synchronization across devices, used by an open-source experimental system UI. Here the system is demoed by 9to5Google.
Goals
The goal of Ledger was to enable seamless transition of user state across devices.
We wanted it to be:
- synchronized across user devices
- private, in the sense that the cloud provider powering the synchronization doesn’t see the data being synchronized
- local-first, so that applications using Ledger can work offline and be performant on flaky Internet connections. We wanted all data to be stored locally, and then copied to other nodes asynchronously.
Design decisions
API surface. We decided to expose a simple key-value store API storing simple byte strings. This allowed for maximum flexibility, as more opinionated and feature-reach APIs, including CRDTs, structured storage, indices, etc. could be built on top.
Representing the state. Similarly to git, we opted for a model where every snapshot of the state is represented as a content-addressed commit, identified by a hash of its content. Conceptually, every commit stored the entire state of the key-value store at a given moment.
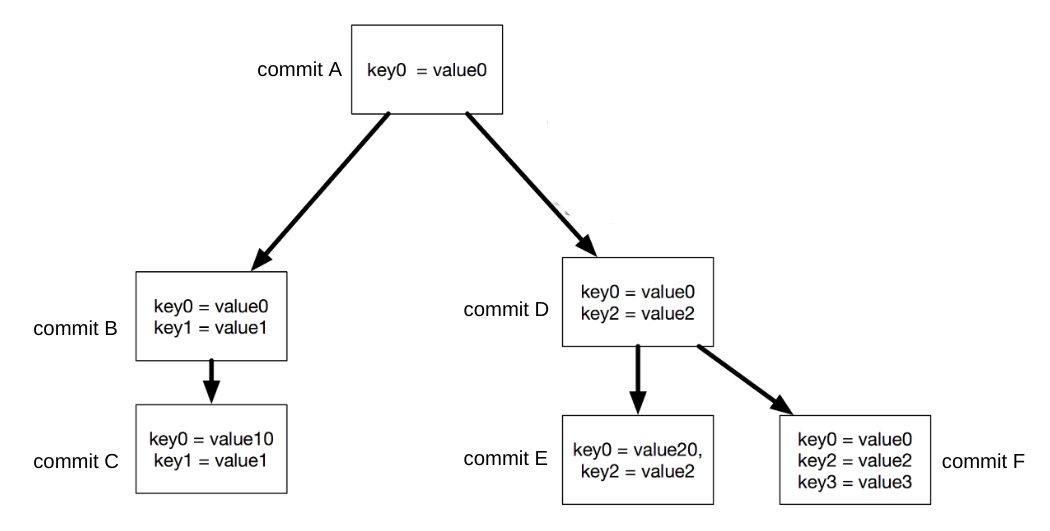
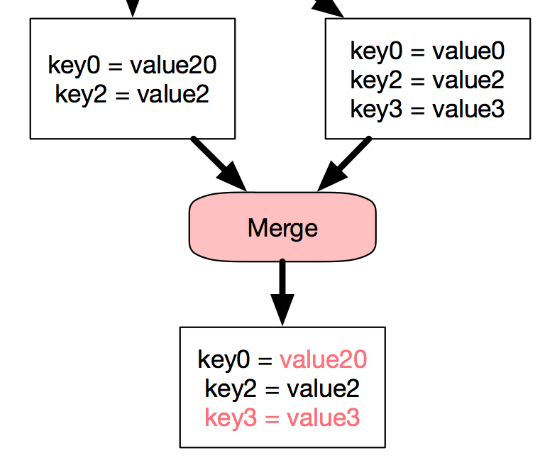
Conflict resolution. Given that Ledger was local-first, we needed to deal with the possibility that the state of the data store may diverge between user devices. We opted out to leave the conflict-resolution configurable by the client app; exposing a hook the app can use to resolve each conflict. We also provided an automatic last-one-win policy for the apps for which that was appropriate.
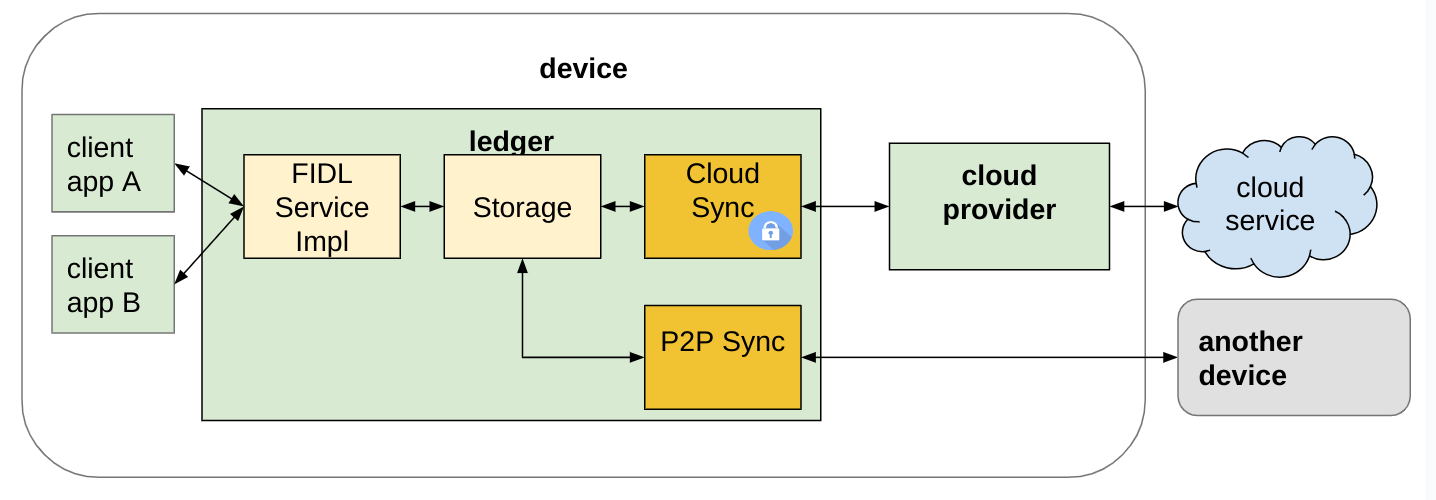
Architecture
Ledger was implemented as a Fuchsia component running on each device. It exposed a local API to client apps over a FIDL protocol.
The system UI orchestrator itself was of those client apps, storing metadata about which apps (stories) the user had active at a time. Thanks to Ledger, these were synchronized between devices.
Efficient local storage
Even though each commit conceptually represents the entire state of the data store, it would be wasteful to store at each commit a separate copy of the data store (which may contain thousands or millions of entries, only one of them changed as compared to a parent).
Structural sharing. To make the local storage efficient, we represented the data store as content-addressed B-trees. Each subtree was content-addressed as well, allowing us to reuse the representation of these subtrees between different commits.
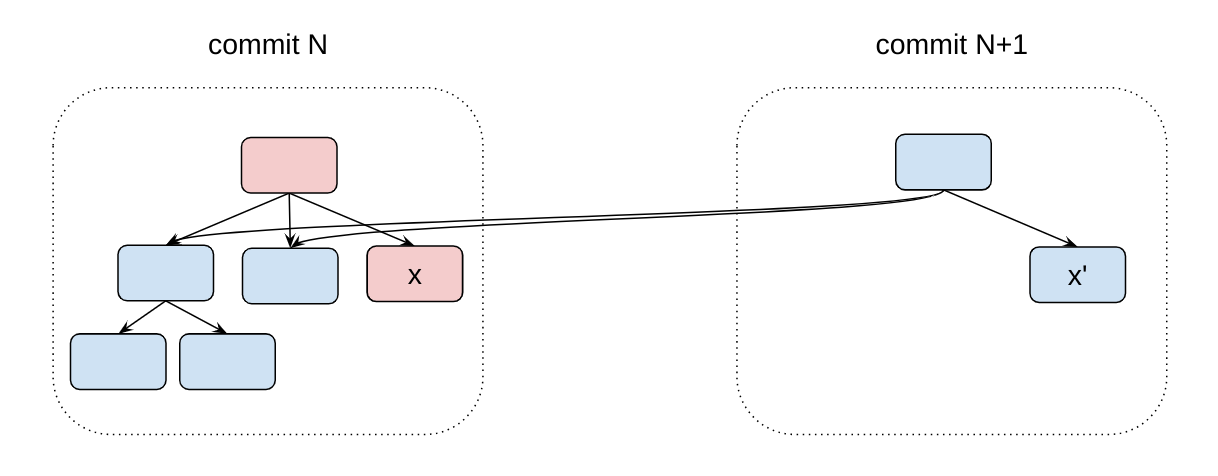
Unique-representation. We modified the classic B-tree data structure to select the level of each node based on the hash of the key. This ensured that our B-trees were uniquely-represented, that is, the shape of the tree wasn’t dependent on the insertion order.
Chunking. We split big values stored in Ledger into chunks, so that chunks can be reused between different revisions of the value. We made the chunk-points content-dependent, so that they are stable in presence of small modifications. (Such as inserting a single character.)

Synchronization
We had implementations for both cloud and peer-to-peer (P2P) sync.
Peer-to-peer sync is nice, because it’s fast and the data doesn’t go through third parties. This means it doesn’t require additional encryption. (Beyond ensuring that the transport protocol is secure in the first place.)
Cloud sync is nice too, because the cloud provider has a lot of durable storage. That’s handy if our device(s) get lost.
Avoiding merge storms. We found that under our git-like design, it was easy to run into merge storms. The scenario is that two devices make a concurrent modification, then exchange the modifications and resolve the conflict concurrently. If the resulting commit is not identical, these commits will be exchanged and need to be resolved again. The cycle can continue for a long time.
To avoid this, we:
- download changes and resolve all conflicts before uploading local state
- require conflict resolvers to be deterministic/content-dependent
- as a last resort, employ randomized exponential backoff when conflict-resolving external changes
Outcome
By mid 2017, we had an early prototype working. Ledger was integrated in an experimental system UI and syncing user state across devices. The end-to-end synchronization latency (from making a write on one device to seeing the results in the UI on another device) was around ~1s, which is about as fast as humans can switch between devices anyway.
Over the next two years we solved some hard problems needed to make the prototype more real: we made local resource management scalable over time (commit pruning, garbage collection), added peer-to-peer synchronization, implemented an end-to-end encryption scheme for cloud sync, set up a dedicated server-side cloud provider and even put together a library of Ledger-based CRDTs for the client apps to use.
As far as experiments go, Ledger was a successful one: it demonstrated that a system with the properties we desired could work and exist. We didn’t find any engineering obstacles to having it work at scale.
So why did we stop working on it? To work on something else :).
Credits
Ledger was a team effort! Thank you to Ambre, Ben, Étienne, Gabriel, Giulio, Guillaume, Jean-François, Maria, Nathaniel, Nelly and Pierre for the fantastic adventure of building it together.