The other day I hit an issue trying to fine-tune an open Large Language Model using the transformers library. Training was crashing, and the error was pretty cryptic:
Function square_i64 was not found in the library
What does that mean? Figuring out what was going on was pretty instructive, so here are my notes.
A tall stack
Deep learning libraries run on a tall stack of software including the the high-level library (transformers, fastai, etc.), the base deep learning library underneath (e.g. pytorch, tensorflow), the GPU support modules it uses to drive hardware (CUDA, Metal) and finally the hardware itself (Nvidia or Apple Silicon GPU).
For example, when using the transformers library, the stack looks like this:
- 🤖 Transformers A library for Natural Language Processing (NLP) tasks, providing various pre-trained models.
- 🔥 PyTorch Popular and versatile deep learning library. Transformers are built on top of pytorch.
- 🎨 GPU support PyTorch comes with GPU support modules that accelerate execution of the computation graph by running the operations on GPUs. The GPU support comes in seperate implementations for each architecture (e.g. CUDA for Nvidia GPUs, Metal for Apple Sillicon)
- 💻 Hardware The actual CPU and GPU on the computer
The crash and disaster tweets
I hit my crash trying to fine-tune the deberta-v3-small model to solve Kaggle Disaster Tweets competition: distinguishing tweets about real emergencies from those that use the same vocabulary in comedic exaggeration (e.g. Running out of white wine. Major disaster).
Below is a minimal example that demonstrates the issue. We’re trying to fine-tune deberta-v3-small with just two data samples: “bazinga”, labelled as 0; and “please-just-work”, labelled as 1.
import pandas as pd
from datasets import Dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from io import StringIO
from transformers import TrainingArguments, Trainer
sample_data = """input,labels
bazinga,0
please-just-work,1
"""
df = pd.read_csv(StringIO(sample_data))
ds = Dataset.from_pandas(df)
model_name = "microsoft/deberta-v3-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenizer_func(x): return tokenizer(x["input"])
ds_tokenized = ds.map(tokenizer_func, batched=True)
dds = ds_tokenized.train_test_split(0.2, seed=42)
args = TrainingArguments(
"outputs", learning_rate=8e-5, warmup_ratio=0.1,
lr_scheduler_type="cosine", fp16=False, evaluation_strategy="epoch",
per_device_train_batch_size=16, per_device_eval_batch_size=32,
num_train_epochs=4, weight_decay=0.01, report_to="none",
)
model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=1)
trainer = Trainer(
model, args, train_dataset=dds["train"],
eval_dataset=dds["test"], tokenizer=tokenizer,
)
# This crashes
trainer.train()The last line crashes with:
2023-11-25 09:29:20.582 Python[15924:310024] Error getting visible function:
(null) Function square_i64 was not found in the library
/AppleInternal/Library/BuildRoots/495c257e-668e-11ee-93ce-926038f30c31/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPSCore/Utility/MPSKernelDAG.mm:805: failed assertion `Error getting visible function:
I was running this program on an Apple Sillicon Macbook. (See more details about my setup.) The error seems to say that some function (square_i64) is missing in MetalPerformanceShaders, which looks like a support library needed to use the Apple Sillicon GPU.
So is it a bug in the Apple GPU support package?
Repro on CUDA
To find out if the issue is specific to Macbooks, let’s run the same program on an Nvidia GPU. I uploaded the repro program as a notebook on Kaggle and run it there on Nvidia P100.
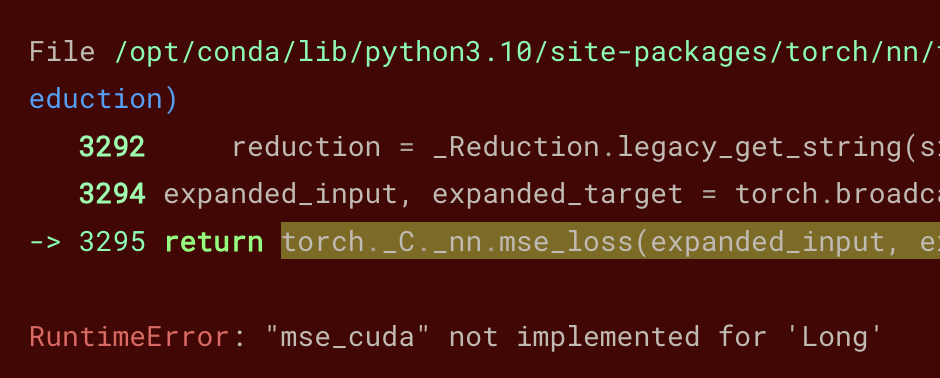
… aha!
So the issue reproduces on both Apple and Nvidia GPUs. It’s not the same error, but it looks similar:
- Apple GPU:
Function square_i64 was not found in the library - Nvidia GPU:
RuntimeError: "mse_cuda" not implemented for 'Long'
Now what?
The loss function
Given that we’re trying to do something pretty basic (fine-tune an NLP model on a tiny data set), and it doesn’t work on the very popular transformers library, it’s very likely that it’s us who are holding something wrong.
The Python stack trace in the output contains a hint: we’re crashing in self.compute_loss(model, inputs). The “loss function” is used to determine how much the results of the neural network deviate from what’s expected. On our tiny example, the model would try to predict the labels for our two strings:
bazinga
please-just-work
And use the loss function to compare the output with the expected labels (0 for bazinga, 1 for please-just-work).
Why do we crash when computing the loss function?
MSE
Based on the Python stack trace, the loss function that’s crashing is mse_loss. That’s a “mean squared error”: the average of squares of differences between the target and the prediction. The error "mse_cuda" not implemented for 'Long' indicates that the function cannot work on ‘Long’, that is, integer values.
In theory, the formula for mean squared error is perfectly applicable to integer numbers. In practice, PyTorch is all about floating-point numbers, and so its CUDA backend doesn’t implement MSE for integers.
The programmer’s instinct is to just align the data types with what the function expects. And indeed, if we change the labels in the input data set to floating point (‘0.0’ and ‘1.0’), the crash goes away. That’s a wrong solution.
Our problem isn’t in MSE not working on integers. Our problem is this: given that the labels are binary, why transformers are using MSE as the loss function in the first place?
Regression vs classification
There are two types of tasks you could this type of model for:
- regression: compute a continuous variable (e.g. how positive is the tone of a message)
- classification: assign a label to a message, e.g. “positive” or “negative”
For each type of task, we’d use a different loss function. Regression is continuous, and is typically evaluated using MSE. But for classification, we’d use a loss function that takes categorical labels as inputs, and computes a continuous value as the output. The standard function in this case is often cross-entropy loss.
In my example, I was using the model to classify tweets as “about a real emergency” or not. Given that my input data had categorical labels (0 or 1), and not continuous values, I was working with a classification problem.
Why transformers were treating it as a regression task?
num_labels and automagic defaults
The answer is in the source code: modeling_deberta_v2.py will automagically treat the task as a regression problem if the ’num_labels’ is set to 1:
if self.num_labels == 1:
# regression task
loss_fn = nn.MSELoss()I never found documentation for ’num_labels’ in the transformers documentation , but by know it’s clear I misunderstood it: num_labels is the number of different label values that can be assigned to a data point (e.g. “0” or “1” in my case), not the number of labels themselves.
Conclusion
So the right fix is simply to change num_labels to 2.
model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=2)Takeaways:
- the num_labels parameter is the number of different possible label values, not the number of labels. If the output is a label “positive” / “neutral” / “negative”, then num_labels should be 3, even though you only apply one label
- transformers have automagic defaults that silently pick different loss functions depending on num_labels
- if you’re crashing in the loss function, first make sure it’s the right loss function for the task
Thank you to Sourab who put me on the right track on huggingface/transformers#27707 👏.